

File photo/NBD
As large language models move beyond conversation into complex task execution, the key concern for developers and enterprises is no longer per-query cost, but the cumulative Token spending of AI agents handling long contexts, multi-step reasoning, and automated workflows.
Against this backdrop, DeepSeek slashed prices over two consecutive days.
On April 25, it introduced a limited-time 75% discount on its V4-Pro API (valid through May 5, 2026). On April 26, it further reduced cached input prices across all models to one-tenth of previous levels, with V4-Pro eligible for stacked discounts.
As a result, cached input costs dropped to 0.02 per yuan million tokens for V4-Flash and 0.025 yuan for V4-Pro—down to as low as one-fortieth of original pricing. At peak discounts, V4-Pro falls to about $0.0037 per million tokens, and V4-Flash to $0.0029, well below leading models like GPT-5.5 and Claude Opus 4.7.
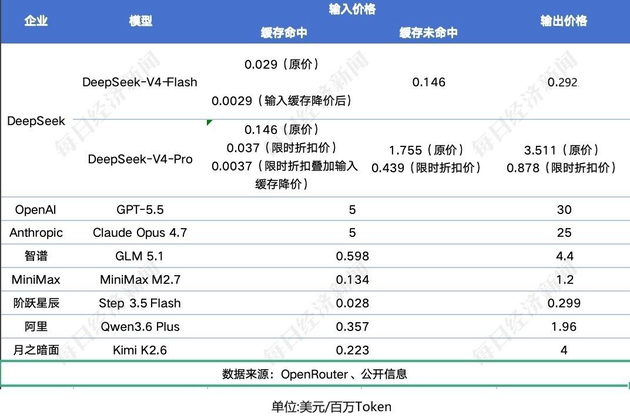
Even before the cuts, V4-Pro cost $5.27 per million tokens, versus $35 for GPT-5.5 and $30 for Claude Opus 4.7. With cache hits, its cost drops to $3.66—roughly one-tenth of GPT-5.5.
According to Hu Yanping, a specially appointed professor at Shanghai University of Finance and Economics, the move is designed to attract developers, enterprises, and agent-based application users.
“Agent workloads tend to consume large volumes of tokens. With V4 reaching top-tier performance levels while maintaining significantly lower pricing than competing models, it is highly attractive to users,” Hu noted. “In recent months, both domestic and international model providers have raised prices substantially. DeepSeek is now pushing the cost baseline downward again.”
Usage has surged accordingly. On OpenRouter, V4-Flash reached 50.2 billion tokens on April 25 (+85.9% day-over-day), while V4-Pro hit 13.6 billion tokens, nearly quadrupling. Flash usage climbed further to 81.4 billion on April 26, though Pro dipped to 9.6 billion.
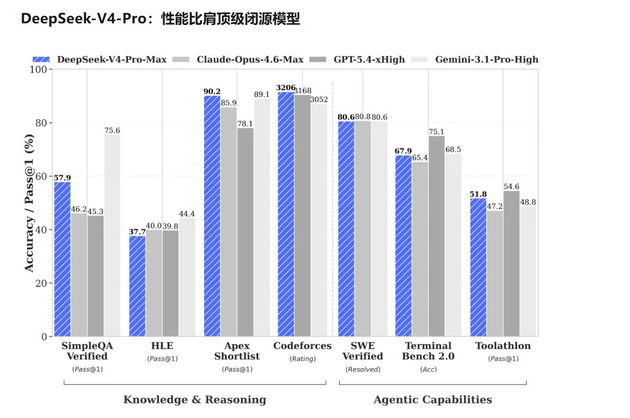
Analysts suggest DeepSeek’s aggressive pricing could lower pricing expectations for other domestic models, including Kimi K2.6, GLM-5.1, Qwen, and MiniMax.
Hu Yanping believes that if domestic inference computing capacity continues to scale, and as agent applications drive higher token consumption, overall token prices could stabilize after recent increases. However, he noted that the impact on top-tier models such as GPT-5.5 and Claude Opus 4.7 may be limited.
Still, DeepSeek’s disruptive entry is reshaping the competitive landscape. For developers and enterprises, a new era—marked by more choices and significantly lower costs—may be arriving faster than expected.

 川公网安备 51019002001991号
川公网安备 51019002001991号





