
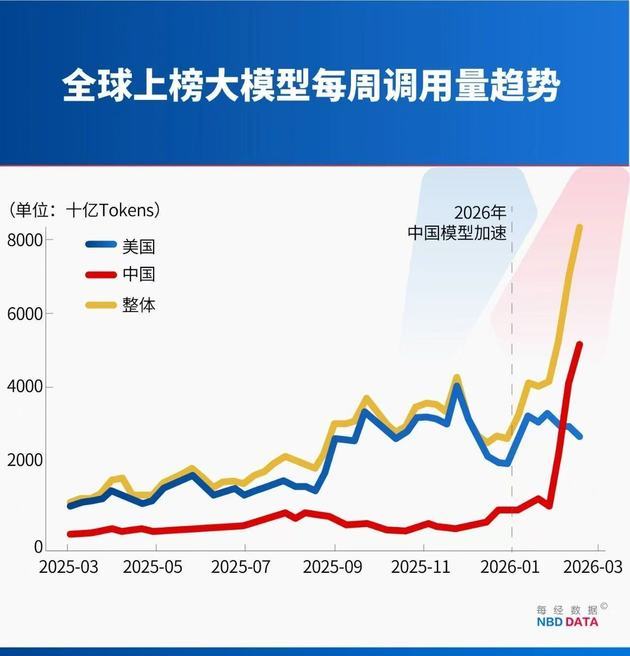
In February, token usage of Chinese AI models exploded, surpassing that of the U.S. for the first time.
Data from OpenRouter, the world’s largest AI model API aggregation platform, shows that in the week of February 9–15, Chinese models recorded 4.12 trillion tokens in usage, overtaking the U.S.’s 2.94 trillion in the same period.
In the week of February 16–22, weekly token usage of Chinese models further surged to 5.16 trillion tokens, up 127% in three weeks, while U.S. models dropped to 2.7 trillion tokens. Meanwhile, four of the world’s top five most-used models are Chinese—a surge driven not by a single hit product, but by the cluster rise of China’s AI firms.
A token is the smallest unit of text processed by AI models. Compared with user counts, token usage is a more accurate measure of real-world usage intensity, user stickiness, and commercial value.
Chinese model developers are capturing global markets via rapid iteration and cost advantages, and demand for domestic computing power is growing exponentially.
China Overtakes U.S. in Token Usage, Four Large Models Lead Global Rankings
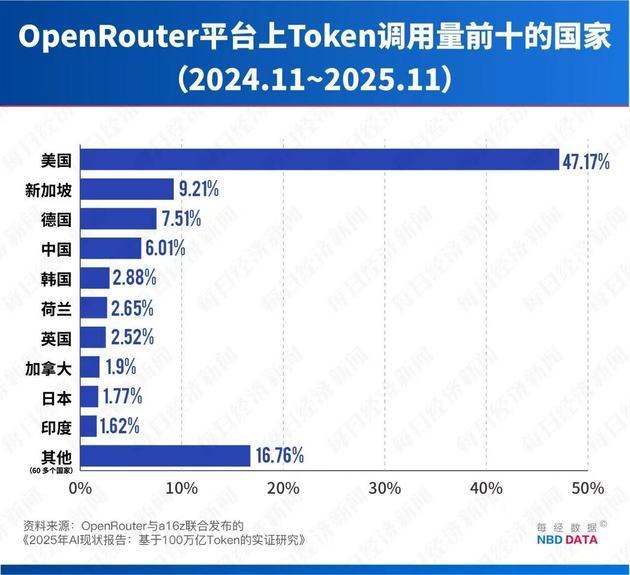
OpenRouter hosts hundreds of large language models worldwide and serves over 5 million developers, making it the largest AI model API platform. Its API usage data is widely regarded as a reliable barometer of global AI adoption, reflecting developers’ real-world choices.
Notably, its user base is dominated by overseas developers, with 47.17% from the U.S. and only 6.01% from China, making its rankings an objective measure of Chinese AI models’ global appeal.
An analysis by National Business Daily of OpenRouter data shows explosive growth in global large-model token usage over the past year. In the week of March 3–9, 2025, weekly usage of the platform’s top 10 models stood at just 1.24 trillion tokens. By mid February 2026, this figure soared to 13.95 trillion—a 10x increase in less than a year.
In 2025, U.S. models drove most growth, accounting for nearly 70% of total token usage among the top 10 models, while Chinese models made up less than 20%. However, entering 2026, U.S. model growth slowed, while Chinese models accelerated sharply.
In the first week of February 2026 (Feb 2–8), Chinese models reached 2.27 trillion tokens, sending a strong signal of catching up.
Just one week later (Feb 9–15), Chinese models officially overtook U.S. models with 4.12 trillion tokens versus the U.S.’s 2.94 trillion—a historic milestone.
The momentum continued: in the week of Feb 16–22, Chinese usage hit 5.16 trillion tokens, expanding the lead with a 127% three week increase.
This strong growth came not from a single star product, but from a cluster rise of Chinese AI companies.
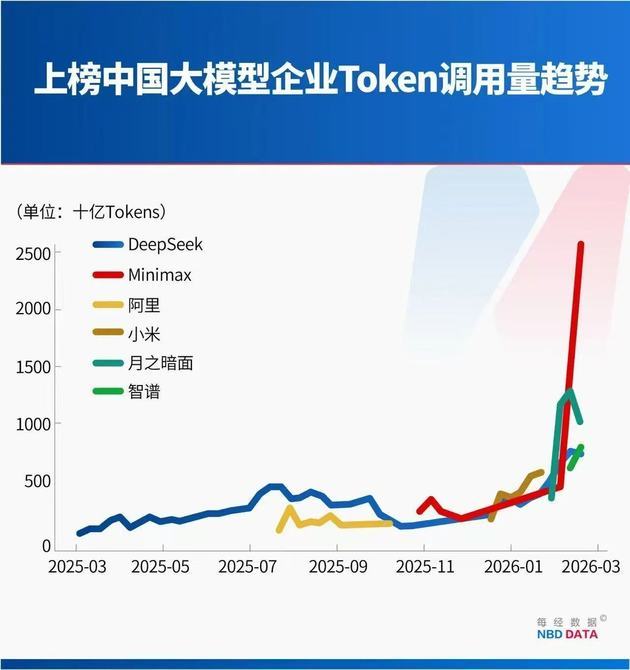
For the week of Feb 16–22, four of the top five models are Chinese:
● MiniMax M2.5
● Moonshot AI Kimi K2.5
● Zhipu AI GLM 5
● DeepSeek V3.2
Together, they accounted for 85.7% of total token usage among the top five models.
MiniMax released M2.5 on February 13, 2026, and it quickly topped weekly usage within days. In the Feb 9–15 surge of 3.21 trillion tokens, M2.5 alone contributed 1.44 trillion.
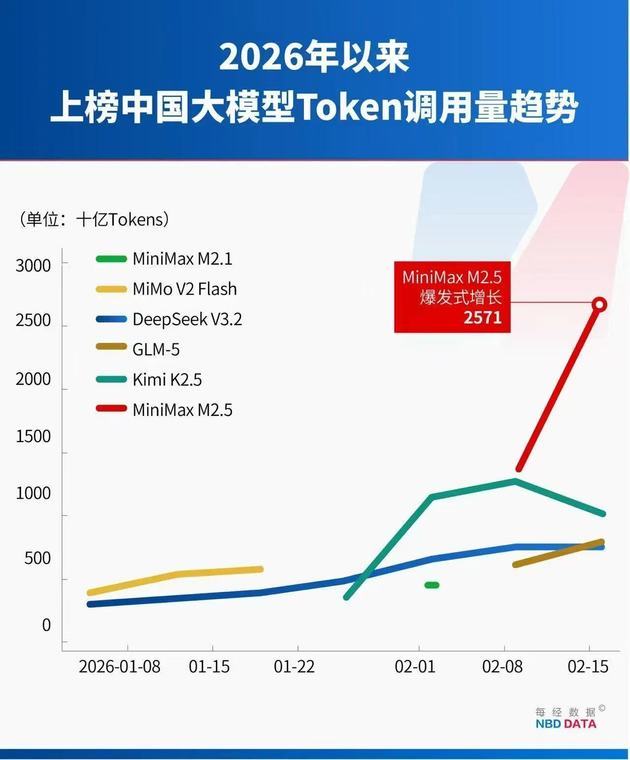
Moonshot AI’s Kimi K2.5, launched January 27, saw continuous usage growth thanks to its native multimodal architecture and powerful parallel Agent capabilities. Within a month of launch, Kimi’s revenue exceeded its full-year 2025 total, driven by surging global paid users and API usage.
Zhipu AI’s flagship GLM 5, released February 12, features a 200K long context window and optimized long range Agent tasks. Its usage reached 0.8 trillion tokens in its second week.
Hu Yanping, Distinguished Professor at Shanghai University of Finance and Economics, coined the term “AI China Team” to describe China’s AI landscape.
He argued that moderate industrial concentration—with a broad tech ecosystem rather than just two or three oligopolies—benefits competition, innovation, and talent, and strengthens China’s cluster advantage against the U.S.
Cost Less Than 1/10 of U.S. Peers—Why Are Chinese Tokens Cost-effective?
Chinese models have won over global developers quickly thanks to performance matching or exceeding top global models, plus unmatched cost advantages.
On OpenRouter’s public pricing:
● Input: MiniMax M2.5 and Zhipu AI GLM 5 cost $0.3 per million tokens. Claude Opus 4.6 costs $5—~16.7x higher.
● Output: MiniMax M2.5 at $1.1, GLM 5 at $2.55, versus Claude Opus 4.6 at $25—~22.7x and ~9.8x higher, respectively.
This gap directly shapes developers’ API choices.
A key driver is architectural innovation, especially the Mixture of Experts (MoE) framework, widely adopted by DeepSeek, Alibaba Qwen 3.5 Plus, and others.
MoE splits a large model into smaller “expert networks” and a gating network. Only relevant experts are activated per task, drastically reducing computation and hardware needs. MoE can cut inference memory usage by 60% and boost throughput by up to 19x.
Beyond algorithmic innovation, Chinese AI firms are pursuing vertical integration: deeply co designing and optimizing model algorithms, cloud infrastructure, and AI chips to maximize efficiency and minimize per token cost.

 川公网安备 51019002001991号
川公网安备 51019002001991号





