
If artificial intelligence (AI) is likened to a child, then the Scaling Law is its crucial "growth code": as long as the "child" is provided with ample "nutrients," namely data, models, and computing power, it can thrive and grow strong.
In 2020, OpenAI published the paper "Scaling Laws for Neural Language Models," proposing the concept of "scaling law," which laid the linguistic foundation for the emergence of large language models. Consequently, the "scaling law" is also seen as the cornerstone of artificial intelligence.
Now, this "scaling law" is also leading the field of robotics to open the door to a new world.
Recently, a groundbreaking discovery was made by a Tsinghua University team. They published a paper "Data Scaling Laws in Imitation Learning for Robotic Manipulation" on the website of arXiv, an open-access repository of electronic preprints and postprints (known as e-prints) approved for posting after moderation, but not peer review.
In the paper, the team investigates whether similar data scaling laws exist in robotics, particularly in robotic manipulation, and whether appropriate data scaling can yield single-task robot policies that can be deployed zero-shot for any object within the same category in any environment.
National Business Daily (NBD) have an interview with one of the authors of the paper, Hu Yingdong, fourth-year Ph.D. student at Institute for Interdisciplinary Information Sciences (IIIS), Tsinghua University.

Hu Yingdong Photo/arXiv
NBD: Could you share your inspirations to explore robotics in embodied intelligence - Data Scaling Laws?
Hu Yingdong: Yes, our exploration of data scaling laws was indeed partly inspired by LLMs. The scaling laws in LLMs have become one of the most fundamental principles today, encompassing three dimensions: dataset size, model size, and total training compute.
Understanding dataset scaling is crucial before exploring model and compute scaling. In simple terms, we discovered that data scaling laws describe a power-law relationship between a robot policy's performance in new environments and with new objects, and the number of environments and objects it encountered during training. Simply put, the more diverse environments and objects included in training, the better the generalization performance.
NBD: In your study, with proper data scaling, a single-task policy can generalize well to any new environment and any new object within the same category. Does this mean that once robots have learned enough data, they don't need to learn any further?
Hu Yingdong: This doesn't mean robots no longer need to learn. While our current success rate of 90% is impressive, it's still not sufficient for commercialization and home use. We need to achieve success rates above 99.9% - after all, you wouldn't want a robot that has a 10% chance of breaking your glass while pouring water.
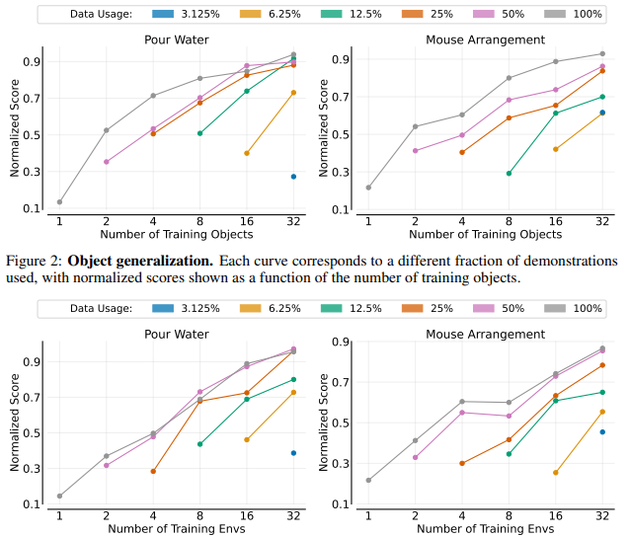
NBD: Your results show that robots are able to adapt to various environments after learning a large amount of data. Is this a sign that we may well see general-purpose robots in the future?
Hu Yingdong: I believe we will see general-purpose robots in the future, though I cannot predict exactly when. Our research has only explored data scaling, and as I mentioned earlier, we haven't fully investigated model and compute scaling yet. There are still many important research questions to address.
NBD: Some articles referred to your findings as "the ChatGPT moment for humanoid robots", what do you make of that? Do you think the moment has come, or are more technological breakthroughs needed?
Hu Yingdong: I don't believe we've reached the ChatGPT moment for humanoid robots yet, though we're rapidly progressing toward that goal. One key characteristic of ChatGPT is its extraordinary generalization ability - its capability to perform well across almost any user-defined task.
While we're emphasizing robots' ability to generalize to new environments and objects, the main difference is that our model isn't yet truly universal and cannot handle the wide variety of instructions that users might give.

NBD: You mentioned that "improving the quality of data may be more important than blindly increasing the amount of data". So, in your view, how can data quality be effectively improved? Is there a specific approach or strategy?
Hu Yingdong: We discussed this in detail in our paper. Data quality has many aspects, but we primarily focus on diversity. We found that given limited resources, it's more beneficial to collect human demonstrations across a wider variety of environments and objects rather than collecting more demonstrations in specific environments with specific objects.
NBD: Your research has now been validated in several real-life scenarios. Do you think these results can be translated into practical applications some day?
Hu Yingdong: I believe this technology will eventually find its way into practical applications. For instance, it could be used in restaurants for service robots. Even more meaningfully, it could be applied in nursing homes to assist in elderly care, which would be particularly valuable and impactful.

 川公网安备 51019002001991号
川公网安备 51019002001991号





